论文题目:All NLP Tasks Are Generation Tasks: A General Pretraining Framework
作者:Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, Jie Tang
单位:Tsinghua Univerisity, Beijing Academy of Artificial Intelligence, MIT
期刊:Arxiv
发表日期:2021.03.18
快速总结
Pre-training
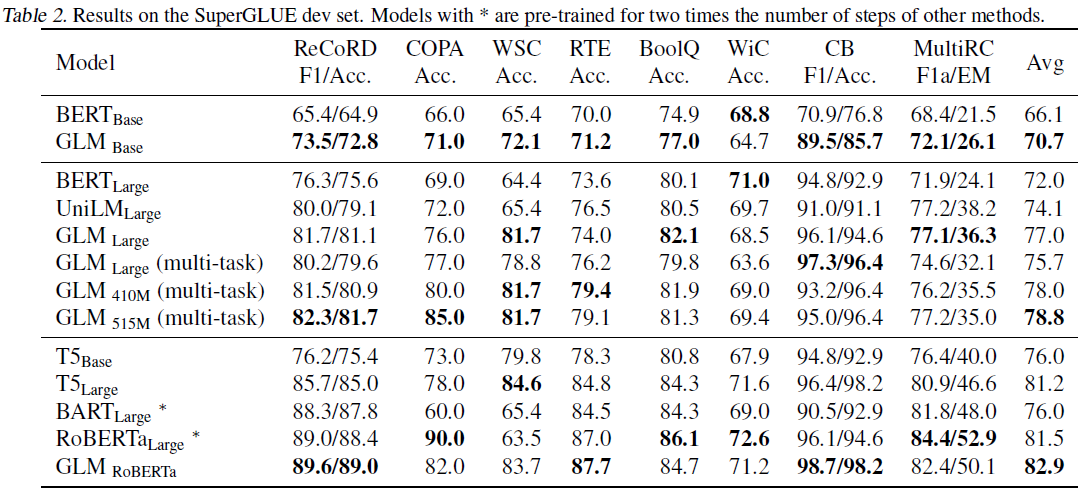
预训练步骤如下图所示:
- 从输入文本$x_1,\dots,x_6$中sample若干span (例子中为$[x_3]$和$[x_5,x_6]$);
- 用[MASK]替换上述span,作为输入的A部分,将sample的span进行shuffle,作为B部分;
- B部分中每个span前后分别加上[START]和[END],训练目标为单项预测B部分,另外分别用两种位置向量作为输入 (如图所示);
- Self-attention的mask控制可以attend的位置,其中A部分只能attend自身,B部分能attend整个A部分以及前面已生成的部分。
Fine-tuning
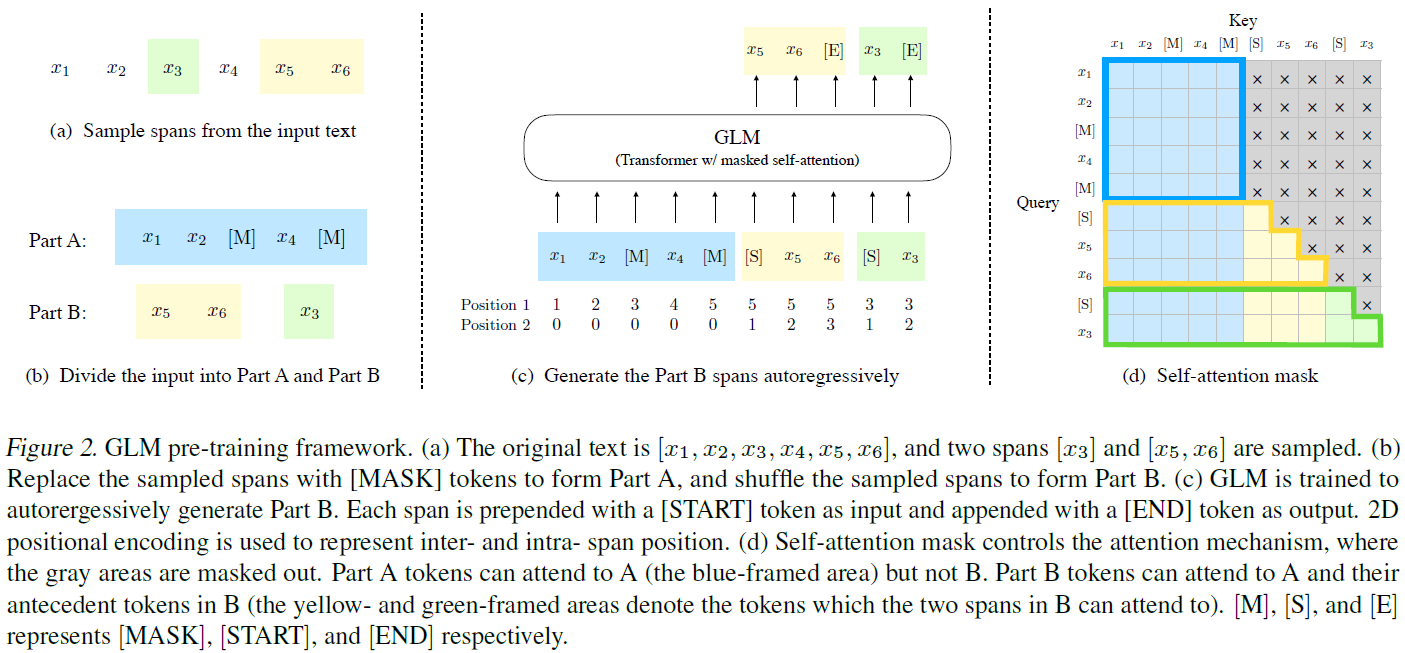
fine-tuning方式如下图所示:
- 针对分类任务,以prompt方式在后面加一句以[MASK]结尾的序列,预测label (参考PET);
- 针对生成任务,直接将该模型以autoregressive模型方式使用。
问题
- 预训练时使用了[START]和[END]符号,但在fine-tuning的时候没有使用?
- 词级别分类任务如何解决?
GLM Pre-training Framework
模型结构
采用了类似BERT的结构,每层由一个multi-head self-attention layer和一个position-wise fully connected feed-forward layer组成。
self-attention layer中的一个self-attention head的定义如下:
$$ A^l = \text{softmax}(\frac{Q^l(K^l)^\top}{\sqrt{d_k}}+M) V^l $$
形式跟BERT中的self-attention layer差不多,主要区别是这里的$M$为self-attention mask,用来控制每个token可以attend的token范围,主要作用是控制A部分只能attend自身,B部分能attend整个A部分以及前面已生成的部分。
而BERT的实现中也有这个mask,其作用是禁止attend到padding部分。
feed-forward layer参考了Megatron-LM (Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism),相对于BERT有以下两点修改:
- 交换了residual connection和layer normalization的位置,根据Megatron-LM论文中第5.3节的实验分析,该修改对于大规模的类BERT模型很重要。
- 在token prediction head中用linear层替换了原来的feed-forward network。在transformers实现的BERT代码中,LMPredictionHead是用的1个dense(hidden_size,hidden_size)层 + 1个激活函数 (GeLU) + 1个layer normalization层 + 1个dense(hidden_size, vocab_size)层组成的FF network实现的。而这里直接只保留了最后一个dense层。
Autoregressive Blank Infilling
这部分基本思想见快速总结里的pre-training部分,简单来说就是把输入分为A、B两部分,其中A部分用[MASK]替换sample出的span,B部分就是这些span。
另外B部分每个span的开头和结尾分别加上[START]和[END]。
A部分只能attend自身,B部分能attend整个A部分以及前面已生成的部分。
这样,模型能从A部分学习一个bidirectional encoder,而从B部分能学习一个unidirectional decoder。
该模型和SpanBERT (SpanBERT: Improving Pre-training by Representing and Predicting Spans) 的主要区别是SpanBERT中未知span的数量是固定的,而GLM中span数量是未知的。
2D Positional Encoding
模型中使用了以下2类位置id:
- 原始位置id:每个token在A部分的位置id,而B部分的位置id为该span在A部分对应的[MASK]的位置id。
- intra-span id:A部分的token这类位置id均为0,而B部分中每个span中这类id都从1开始一直到该span中的最后一个。
上述两类位置id使用两个独立的位置向量表,并且输入时直接与输入token向量相加。
预训练目标
预训练目标为从左到右地生成被遮盖的span。
与BERT相同,遮盖的token占比为15%。
实验中发现遮盖比例对下游任务性能至关重要。
与BART (BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension) 相同,span的长度按照$\lambda=3$的泊松分布 (Poisson distribution)确定:
$$ P(X=k)=\frac{\lambda^k}{k!}e^{-\lambda}, k=0,1,\dots $$
泊松分布的期望和方差均为$\lambda$。
且重复sample直到span总长度达到原始文本的15%为止。
使用上述的sample方法训练的模型由于span长度有限,仅适用于NLU任务。
为了实现将一个模型同时用于NLU和文本生成任务,本文还测试了multi-task pre-training。
具体来说,增加了另一种sample span的方式,即从一个原始文本长度的50%-100%的均匀分布 (uniform distribution) 中sample span的长度,且每个文本只sample一个span。
其训练目标跟上面一样。
总的来说,multi-task pre-training中使用了两种sample策略:
- 按照$\lambda=3$的泊松分布确定span的长度进行sample,重复直到span总长度达到原始文本的15%为止。
- 按照原始文本长度的50%-100%的均匀分布确定span长度进行sample,每个文本中只sample一个span。
通过这种方式,本文实现了训练一个模型同时用于NLU和文本生成任务。
Fine-tuning GLM
为了解决BERT中预训练和fine-tune阶段不一致的问题,本文将NLU分类任务视为blank filling的生成任务,参考了PET (Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference)。
例如,对于情感分类任务,可以将输入文本$x$转化为[SENTENCE]. It's really [MASK],记为$c(x)$。
而原始标签$y$则通过一个verbalizer $v(y)$映射为填空的答案。
例如,在情感分类任务中,positive和negative分别被映射为good和bad。
输入文本的情感极性与模型预测good或bad的概率成正比,也就是说给定输入文本$x$,情感极性$y$的条件概率为:
$$ p(y|x) = \frac{p(v(y)|c(x))}{\sum_{y’\in\mathcal{Y}}p(v(y’)|c(x))} $$
文中给出的GLM优点有二:
- GLM比BERT更适合解决blank filling任务,因为BERT需要首先确定[MASK] token的个数,而GLM不用。
- GLM在生成过程中打破了BERT的独立性假设 (每个词依赖于前面生成的词)。
对于文本生成任务,直接将GLM作为autoregressive模型使用。
具体来说,将输入的context作为模型的A部分,后面加上[MASK],然后autoregressive地生成B部分。
Cloze Questions and Verbalizers
本文在prompting方面参考了It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners的方法,具体在SuperGLUE数据集上使用的Prompt和Verbalizer如下。

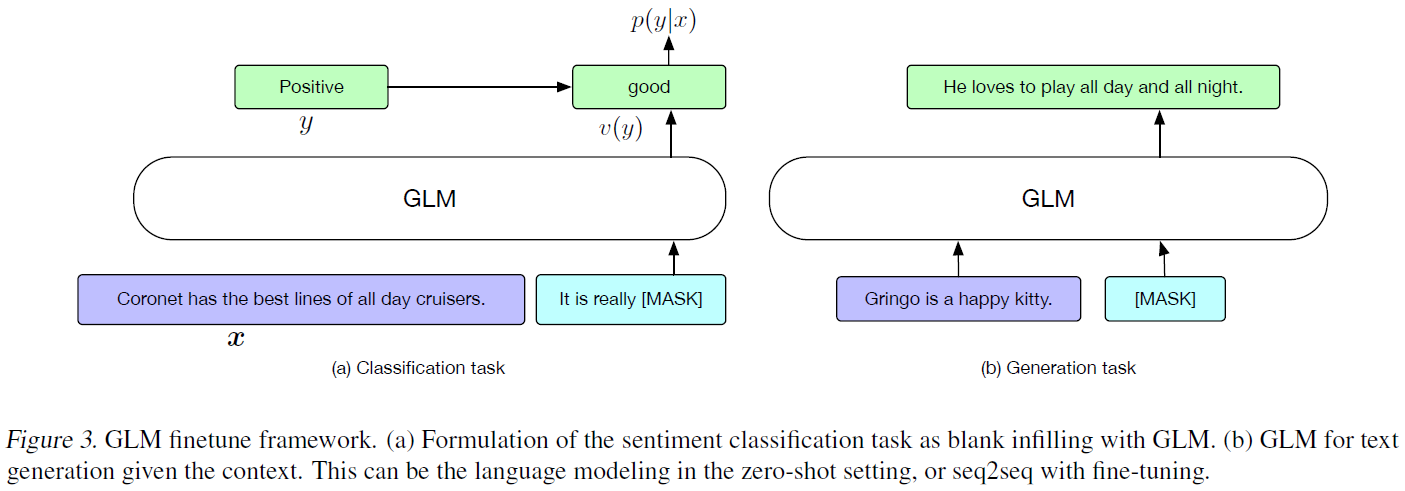
实验
主实验是在SuperGLUE的开发集上跑的,分别对比了预训练目标中介绍的两种目标训练的模型,以及一个更大的使用了RoBERTa数据、分词、超参的模型。
奇怪的是虽然2.5.2节里介绍了GLM和XLNET的区别,但实验里并没有跟XLNET比较。
实验结果如下。