论文题目:ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
作者:Yu Sun, Shuohuan Wang, Shikun Feng, Siyu Ding, Chao Pang, Junyuan Shang, Jiaxiang Liu, Xuyi Chen, Yanbin Zhao, Yuxiang Lu, Weixin Liu, Zhihua Wu, Weibao Gong, Jianzhong Liang, Zhizhou Shang, Peng Sun, Wei Liu, Xuan Ouyang, Dianhai Yu, Hao Tian, Hua Wu, Haifeng Wang
单位:Baidu Inc.
期刊:Arxiv
发表日期:2021.07.05
快速总结
本文贡献包括以下2点:
- ERNIE 3.0模型结合了auto-regressive和auto-encoding两种network,因此能既能处理NLU也能处理生成任务。
- 训练了10B参数的模型,在54个中文NLP任务上取得SOTA效果,在英文SuperGLUE上取得了第一 (2021.07.03)。
另外继承了ERNIE的主要优点,即融入了外部知识。
总的来说,相比于其他预训练模型ERNIE 3.0特点是使用Transformer-XL结构和Document LM预训练任务强化了模型处理长文本的能力。
最大贡献是提出了Knowledge-aware Pre-training预训练任务,将结构化知识图应用于预训练中。
另外一个比较有意思的trick是progressive learning,在warm-up时将输入文本长度、batch size和dropout rate与学习率同步增加。
ERNIE 3.0
整体模型框架
整体模型框架如下图所示,总的来说,ERNIE 3.0使用了Continual Multi-Paradigms Unified Pre-training Framework。
具体来说,在训练时采用了ERNIE 2.0 (ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding) 的continual multi-task learning framework,在训练时使用了多种不同paradigm的任务。
而在模型结构上共享底层参数 (Universal Representation Module),用于获取词汇、句法等通用的抽象特征,在顶层对不同任务使用独立参数 (Task-specific Representation Modules),用于获取特定任务的特征。
实现中使用了2个Task-specific Representation Modules,分别用于处理NLU任务和NLG任务。
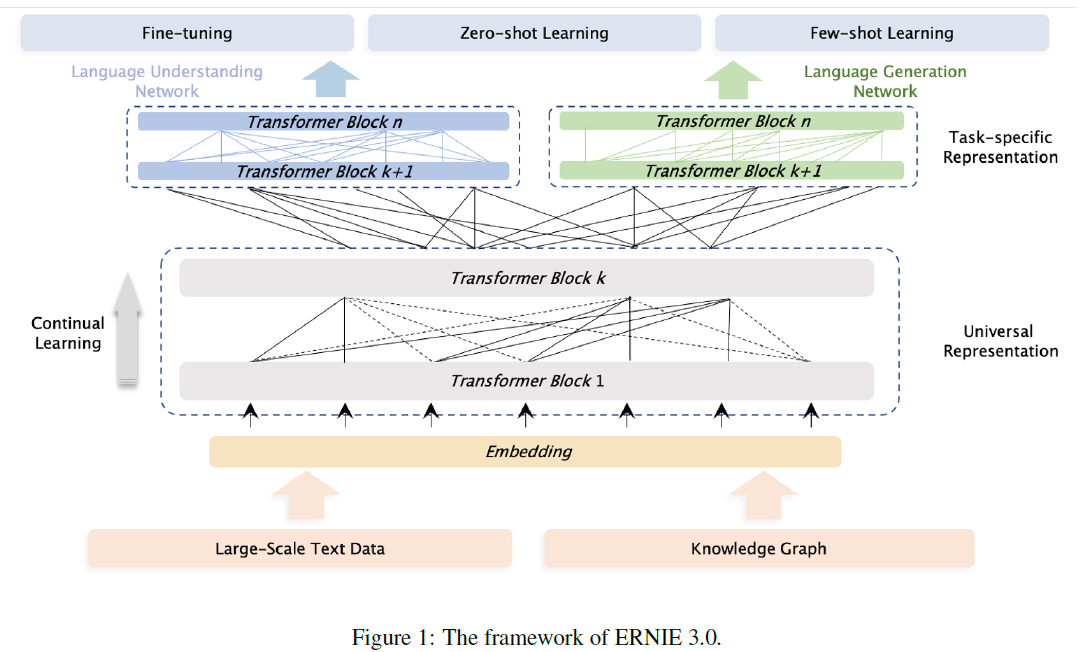
Universal Representation Module
这部分使用了Transformer-XL (Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context) 网络,其在普通transformer基础上增加了一个recurrence memory module用于建模长文本,避免了普通transformer中由于输入长度限制不得不对长文本进行切分从而导致损失长距离依赖的问题。
为了保证共享参数部分有足够大的模型容量来捕获和保存通用的词汇、句法等信息,ERNIE 3.0采用了large size的Universal Representation Module。
Task-specific Representation Module
这部分同样使用了Transformer-XL,但使用了base size模型。
相对于使用MLP或普通transformer作为task-specific层,该选择有3个优点:
- Transformer-XL比MLP或普通transformer捕获信息能力更强;
- 使用base size保证了不会显著增加模型参数量;
- 实际应用时可以固定底层参数共享模块,只fine-tune上层小规模的task-specific模块。
这三点有点强行解释的感觉…
预训练任务
在预训练中本文使用了3类预训练任务。
Word-aware Pre-training Tasks
- Knowledge Masked Language Modeling:ERNIE 1.0 (ERNIE: Enhanced Representation through Knowledge Integration) 中提出的将短语 (phrase) 和命名实体 (name entity) 一起mask后进行预测的任务。
- Document Language Modeling:在普通的LM任务基础上,为了强化对长文本建模的能力,增加ERNIE-Doc (ERNIE-Doc: A Retrospective Long-Document Modeling Transformer) 中提出的Enhanced Recurrence Memory Mechanism,做法是把传统recurrence Transformer中的shifting-one-layer-downwards recurrence改为same-layer
recurrence.
Structure-aware Pre-training Tasks
- Sentence Reordering:ERNIE 2.0中提出的句子重排序任务,将输入段落切分成1到m段并打乱顺序,然后让模型以多分类的形式预测正确的顺序。 (类别为所有可能的句子顺序)
- Sentence Distance:最原始的next sentence prediction (NSP) 任务的扩展,形式为3分类问题,目标是预测两个句子的关系:1.相邻;2.不相邻但来自同一文档;3.来自不同文档。这是一个较常用的预训练任务。
Knowledge-aware Pre-training Tasks
- Universal Knowledge-Text Prediction:该任务是Knowledge Masked Language Modeling的扩展,需要结构化的知识图和对应文本。形式如下图所示,给定一个知识图和对应的文本 (来自百科全书),随机mask三元组中的关系或者文本中的词。模型在预测三元组中的关系时,需要找到对应句子中的head和tail词并确定他们之间的语义关系;而模型在预测句子中的词时,则需要同时考虑句子中的依存信息 (dependency information) 和三元组中的逻辑关系 (logical relationship)。
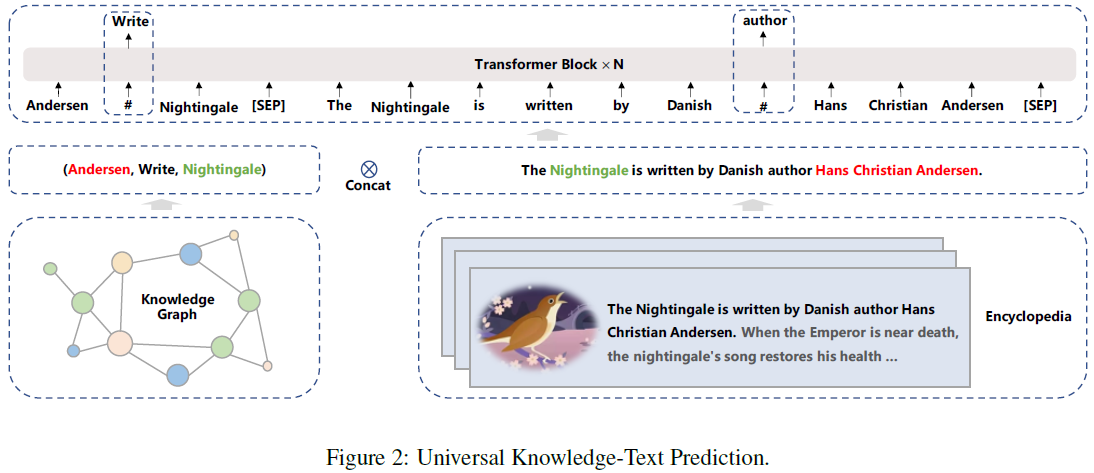
实践中,获取知识图和对应文本的流程为:给定百科全书中的一个文档,首先搜索候选三元组,要求是其head或tail entity是该文档的题目 (按照原文理解这里应该是题目,但是我感觉是不是应该只要出现在文档中就算?也可能是我理解错误,因此把这段的原文放在下面)。然后从候选三元组中选出head和tail出现在同一个句子中的三元组。
|
|
文中给出了上述几个预训练任务的作用:
- 使用knowledge masked language modeling任务训练NLU网络增强其捕获词汇信息的能力;
- 使用sentence reordering和sentence distance discerning任务增强模型捕获句法信息的能力;
- 使用universal knowledge-text prediction任务增强模型对知识的记忆和推理能力;
- 使用document language modeling任务训练NLG网络增强其生成不同风格的文本的能力。
总的来说,感觉在预训练任务这块,本文主要贡献是提出了Universal Knowledge-Text Prediction任务。其他任务基本都是使用此前的工作提出的。另外可以看出ERNIE 3.0中对于长文本的处理比较重视,在结构上使用了Transformer-XL,在任务上使用了Document LM都是为了增强模型处理长文本的能力。
预训练细节
Progressive Training
为了加快预训练过程中的模型收敛速度,本文提出了逐渐增加训练正则因子 (training regularization factor) 的方法。
具体来说就是在训练过程中逐步且同时增加输入序列长度、batch size、学习率和dropout rate。
在一般的transformer训练中都会使用warm-up策略逐步增加学习率,本文提出了将batch size等其他因子同时增加的策略。
预训练数据
在训练时使用了4TB来自11个类别的中文语料,超过了目前中文的所有预训练语料库:
- CLUECorpus2020 (100GB)
- Chinese multi-modal pre-training data (300G)
- WuDaoCorpus2.0 (2.3TB中文,300GB英文)
- PanGu Corpus (1.1TB)
模型超参
- universal representation module: 48 layers, 4096 hidden units and 64 heads;
- task-specific representation modules: 12 layers, 768 hidden units and 12 heads;
- 激活函数: GeLU
- maximum sequence length of context: 512;
- memory length of language generation: 128;
- batch size (all pre-training tasks): 6144;
- optimizer: Adam, lr=1e-4, $\beta_1$=0.9, $\beta_2$=0.999, L2 weight decay=0.01, lr warm-up: 10,000 steps, linear decay;
- trained for a total of 375 billion tokens with 384 NVDIA v100 GPU cards;
- framework: PaddlePaddle.
实验
在54个中文NLP任务上取得了SOTA结果 (包括fine-tuning在NLU和NLG上以及zero-shot learning),同时在英文SuperGLUE上也取得了当时最好结果。
由于实验太多这里就不列了。