论文题目:X-FACTR: Multilingual Factual Knowledge Retrieval from Pretrained Language Models
作者:Zhengbao Jiang, Antonios Anastasopoulos, Jun Araki, Haibo Ding, Graham Neubig
单位:Carnegie Mellon University, George Mason University, Bosch Research
期刊:EMNLP 2020
发表日期:2020.10.13
快速总结
- 构建了23个类型不同的语言上的事实知识检索 (Factual Knowledge Retrieval) 数据库Crosslingual FACTual Retrieval benchmark (X-FACTR);
- 此前类似数据库 (LAMA) 只考虑了single-token entities (例如:“France”),而X-FACTR考虑了multi-token entities (例如:“United States”);
- 语言包括:English, French, Dutch, Spanish, Russian, Japanese, Chinese, Hungarian, Hebrew, Turkish, Korean, Vietnamese, Greek, Cebuano, Marathi, Bengali, Waray, Tagalog, Swahili, Punjabi, Malagasy, Yoruba, and Ilokano;
- 所有语言来自11个语族 (the Indo-European ones include members of the Germanic, Romance, Greek, Slavic, and Indic genera),使用10种不同的文字 (scripts);
- 提出一种基于code-switching-based方法用于增强跨语言预训练模型中知识的方法。

分析实验
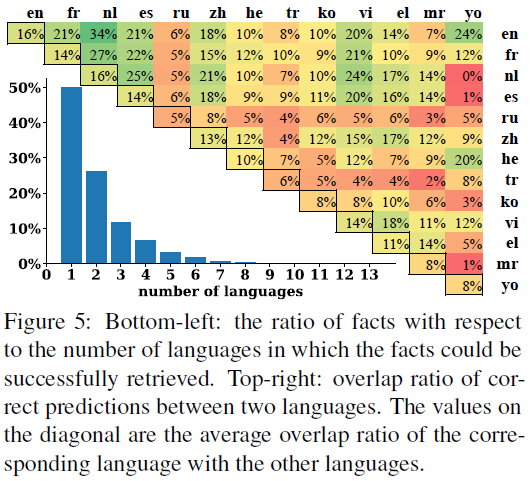
- 超过一半的fact只在一种语言中预测正确;
- 只有3%的fact在超过5种语言上预测正确;
- 最高的英文和荷兰语之间只有34%的fact同时预测正确。