图像语言预训练模型 (Vision-Language Pre-trained Model,VLPM) 总结。
主要参考论文Vision-and-Language Pretrained Models: A Survey和Trends in Integration of Vision and Language Research: A Survey of Tasks, Datasets, and Methods。
VLPM主要由以下四个部分组成:
- 视觉/语言输入数据:原始数据,句子和图片
- 视觉/语言表示:各自独立的表示
- 视觉-语言交互模型:通过模型实现跨模态交互
- 视觉-语言表示:跨模态表示
输入处理
文本编码
基本所有工作都使用了BERT形式的预处理,即将token/position/segment embeddings加起来。
一般token和position embedding基本与BERT相同,而segment embedding则修改为modality embedding来区分不同的模态。
此外也可以在文本表示中插入visual feature作为第4种embedding,作为early-fusion strategy。
这样做的好处是可以用BERT进行初始化,同时也能直接在上层模型中使用transformer encoder和其中的multi-head self-attention mechanism实现跨模态交互。
模态内处理(Intra-modality)
有些工作在处理文本时使用类似BERT的transformer建模上下文信息,从而和使用CNN抽取的高层次图像信息平衡,并强化单模态表示。
图像编码
输入图像一般是与输入文本对齐的图片或者一组相互之间语义相关的图片。
图像一般也用BERT形式的3个embedding表示。
其中segment embedding跟文本处理中一样用于区分模态。
而另外两种则变成visual feature和spatial position embedding用于获取图像语义。
其中visual feature使用CNN抽取。在获取该信息时,granularity of representation(即如何对像素进行分组,将其变成连续的visual tokens)决定了图像中跨模态对齐的粒度。
具体实现包括:
- RoI-based VLPM:使用预训练的R-CNN object detector抽取图像中的识别出的物体区域的图像特征作为visual tokens。该方法建立在假设大部分图像-文本对中的文本都是描述图像中的显著物体(salient object)的。
- paches:将整个图片分为连续的小块。
- pixels:将图片分为更细粒度的像素组,然后使用CNN进行特征抽取。
后两种方法在速度上有较大提升。
最近甚至有不使用CNN而是直接用线性映射paches/pixels的方法(ViT)进一步加速该过程。
此外,也有通过pool layer将整个图片作为visual token的工作。
而在表示spatial position embedding时:
- RoI-based VLPMs一般采用基于坐标的位置embedding(coordinate-based position embedding),例如使用5维向量表示RoI bounding box的坐标和fraction of image area。
- paches/pixel-based VLPMs一般采用2D向量表示行、列数。
另外,由于文本处理的transformer是上下文相关的而图像处理的CNN是local的,因此很多工作会额外对visual tokens使用self-attention transformer使其获取上下文信息使其与文本表示有类似的特征分布。
V-L交互模型
Self-attention-based V-LIM
拼接文本和图像表示,然后输入self-attention transformer。通过transformer实现跨模态(V-L)和模态内(V-V,L-L)的信息交互。
之后,多模态序列中的特殊token(例如[CLS])被用于作为joint V-L表示。
而文本、图像各自对应的输出表示可以用作上下文相关的V-L语义表示。
Co-attention-based V-LIM
用两部分transformer block分别对文本和图像建模,然后只在cross-attention sub-layers里进行交互。
具体来说,cross-attention sub-layers用于强化两种模态的self-attention模块中的key和value的交换。
VSE-based V-LIM
Visual-Semantic-Embedding(VSE)-based cross-modal contrastive learning:
- 首先分别获取单模态表示;
- 然后在图像、文本表示之间学习一个基于相似性的跨模态对齐,从而使其达到一个公共的VSE空间。
这类方法优点是比前两种方法速度更快,资源消耗更少。由于独立计算文本、图像表示,可以支持表示的预计算。
主要应用于大规模跨模态检索。
预训练
数据集
最常用的两个预训练数据集:
- Conceptual Captions (CC, roughly 3M)
- SBU Captions (SBU, around 1M)
此外还有更大的数据集:
- WIT (400M)
- ALIGN(1.8B)
以上数据集都是从网络收集的,研究发现训练集数据量越大在下游迁移任务中性能越好。
此外还有将数据集分为in-domain和out-of-domain数据的,其中一般将CC和SBU视为out-of-domain数据,而将MS-COCO (COCO)/Visual Genome (VG)视为in-domain数据,因为一般下游任务都是建立在这两个数据集上的。
in-domain数据也可以是具体的下游任务的,例如GQA和VQA2.0。
预训练任务和目标
Cross-modal Masked Language Modeling (CMLM)
修改自BERT的MLM任务,目标是根据上下文中的文本和所有visual token预测被mask的token。该任务被证明能将BERT迁移到多模态setting,因此成为一个基本的预训练任务。大部分工作跟MLM一样对subword进行mask,也有工作尝试mask整词和segment,得到了更好的迁移性能。
Cross-modal Masked Region Modeling (CMRM)
最初在RoI-based VLPMs中被提出,包括三个目标:
Region Label Classification (CMRMC):预测每个被遮盖的区域的物体类别(object class),损失函数为cross-entropy loss,将object detector检测到的独热物体类别作为标签,使用VLPM表示做多类别预测。
Label Distribution Approximation (CMRMD):为了缓解object detector可能出现的分类错误,该方法将其预测的类别分布作为soft supervision,优化object detector预测的类别分布和VLPM预测的类别分布之间的KL散度loss。
Region Feature Regression (CMRMR):学习使用L2 loss将VLPM中每个被mask的区域的输出表示回归到其输入特征(来自object detector)。该目标一般与前两种方法共同使用,用于强化图像内容建模的鲁棒性和跨模态学习。
Cross-modal Alignment (CA):
在attention-based模型中一般被视为二分类问题,根据V-L表示判断输入的图像-文本对是否是匹配的,使用二元cross-entropy loss。
在VSE-based模型中则一般被视为排序问题,根据给定的文本或图像找到最匹配的另一方,使用contrastive learning objective。
此外也有使用更细粒度的(patches/pixels)对齐目标的。该目标语前面方法的主要区别是前面方法会引入负例,研究证明这对于fusion-based VLPM和attention-based V-LIM有害。因此有工作对global-level CA使用单模态encoder,但同时对其他任务仍然使用fusion-based encoder。
针对V-L生成任务(例如Image Generation),有工作将CMLM扩展为seq2seq CMLM作为额外的预训练任务。
从另一个角度,也有直接使用某些下游任务(例如IC)进行预训练,称为downstream-driven pretraining task。
也有一些工作同时在单模态数据上进行预训练。
下游任务
Visual Question Answering (VQA)
- 任务描述:可以认为是QA任务的延伸,要求根据输入图片回答问题,答案形式可能是多选一或者生成文本。
代表数据集:
VQA2.0:训练/开发/测试集图片文字对数量=443K/214K/453K。
例子:

KVQA:需求额外知识的VQA。
例子:

解决方案:大多数工作将该任务视为一个多分类任务,即从一系列常见回答中选出一个作为答案。SimVLM通过decode方法生成开放域答案。
Cross Modal Retrieval (CMR)
- 任务描述:根据文本描述从更大的图像库中提取最相关的图像,或者反过来,根据图片检索。(或者称为Image-Text Retrieval)
代表数据集:
- Flickr30K:31,000图片,每张图片对应5个caption。(一般开发、测试各1,000张图片,其余用于训练)
例子:

MSCOCO:训练/开发/测试图片数=165,482/81,208/81,434。每张图片对应5个catption。同时还标注了图片中的物体类别及边界(instance segmentation),常被用于预训练V-L模型。
例子:
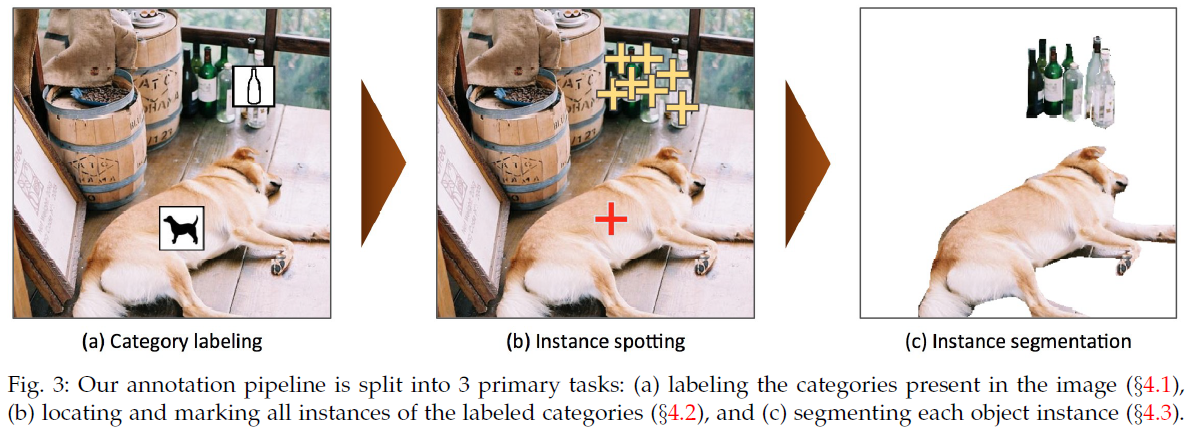
解决方案:部分工作将该任务视为二分类任务,判断每个图像-文字对是否是匹配的。也有工作将其视为排序任务,最大化正例对的表示相似度,最小化负例对的相似度。(使用cross-entropy或者contrastive loss)
Visual Entailment (VE)
任务描述:可以认为是NLI任务的扩展,要求判断图片是否符合文本的描述。
代表数据集:SNLI-VE:训练/开发/测试集图片数=29,783/1,000/1,000。训练/开发/测试集文本数=176,932/5,959/5,973。(这里文本指的是entailment/neural/contradition各自的数量,如例子所示每个图片对应多个不同的描述,也就是说合计数量是3倍)
例子:

- 解决方案:一般视为二分类任务。
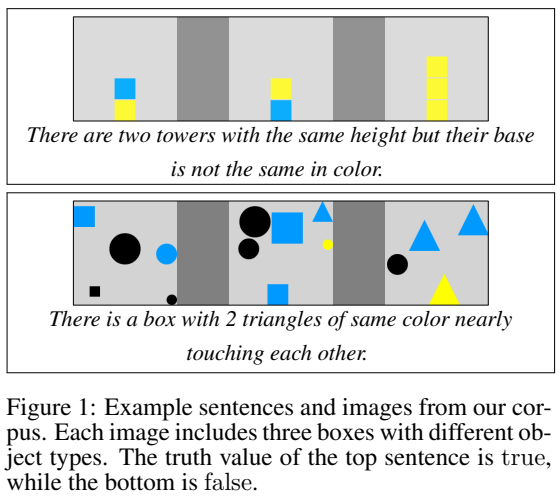
Visual Reasoning (VR)
- 任务描述:根据两张图片判断文本描述是否正确。
代表数据集:

Visual Commonsense Reasoning (VCR)
- 任务描述:包括两个子任务:VQA(根据图片从4个答案里选择1个回答问题)和Answer Justification(根据图片问题和答案从4个选项里选择一个作为选择该答案的原因)
代表数据集:
- VCR benchmark:训练/开发/测试问题数=212,923/26,534/25,263,每个问题对应4个答案和4个原因,训练/开发/测试图片数=80,418/9,929/9,557。图片来自电影片段,包括人类能轻易理解,但机器难以理解的复杂场景。将图片和电影描述提供给标注者,要求其针对图片提1到3个问题并给出答案和原因,另外3个负例则通过使用BERT模型建模问题-答案相关性、答案-答案相似性在其他问题的答案中搜索得到。具体标注的内容包括:图片中检测到的若干物体(使用Mask-RCNN自动识别,过滤后保证每个图片中有至少3个高置信度的物体),每个物体对应的bounding box,问题(query)中包括普通文本和对应图中物体的指针。答案和原因的组成形式也和问题一样。
例子:

解决方案:每个任务是从4个选项中预测一个,因此一般被视为多分类任务。
Referring Expression Comprehension (REC)
- 任务描述:该任务一般对每个图像区域进行分类,判断其是否是当前短语描述的目标。(也称为Grounding Referring Expressions或者Visual Referring Expression或直接叫Referring Expression)
代表数据集:
RefCOCO:由两组标注人员通过ReferitGame(具体描述见该论文)进行标注,首先给A标注者一张标有目标物体的图片,要求其用语言描述,之后B标注者被要求根据图片和描述点击对应的图片。如果B标注正确则得分并交换位置。这里使用的图片包括两个以上属于同一类型的物品。平均长度3.61词。
RefCOCO+:与RefCOCO标注方法相同,但A标注者被要求不能使用列在禁忌词表上的方位词对物体进行描述。平均长度3.53词。
RefCOCOg:一组标注者被要求使用文字描述图片中的物体,另一组则被要求根据图片和描述点击对应物体。标注过程不是互动式的。平均长度8.43词。
例子:

解决方案:在预测时选择分数最高的区域。
Phrase Grounding (PG)
- 任务描述:与REC任务类似,但是要求对齐文本中的短语和图片中的物体。
代表数据集:
Flickr30k Entities:在Flickr30k的基础上标注了句子里的短语和图片中物体的对应关系。
例子:

Visual Relationship Detection (VRD)
- 任务描述:判断图片中两个物体的关系。
代表性数据集:
VRD:关系包括了动作、空间、介词、对比、动词。包括5,000张图片,100个物体类别和70种谓语关系(这里把两个object之间的实际关系称为predicate,而两个object和一个predicate组成的三元组称为relationship),6672种关系类别,实际包含37,993个关系。
例子:

解决方案:
- 视为排序任务,对所有可能的两个物体区域中的subject-predicate-object三元组进行排序。
- 或视为二分类任务,判断给定的subject-predicate-object三元组是否正确。
Visual Dialogue (VD)
- 任务描述:要求AI agent与人类就图片内容开展聊天。
代表性数据集:
VisDial v0.9/v1.0:v0.9训练集/开发集包含82,783/40,504张图片,v1.0将v0.9的两部分数据合并为训练集,然后增加了2,064张图片用于开发集和8,000张图片用于测试。
例子:
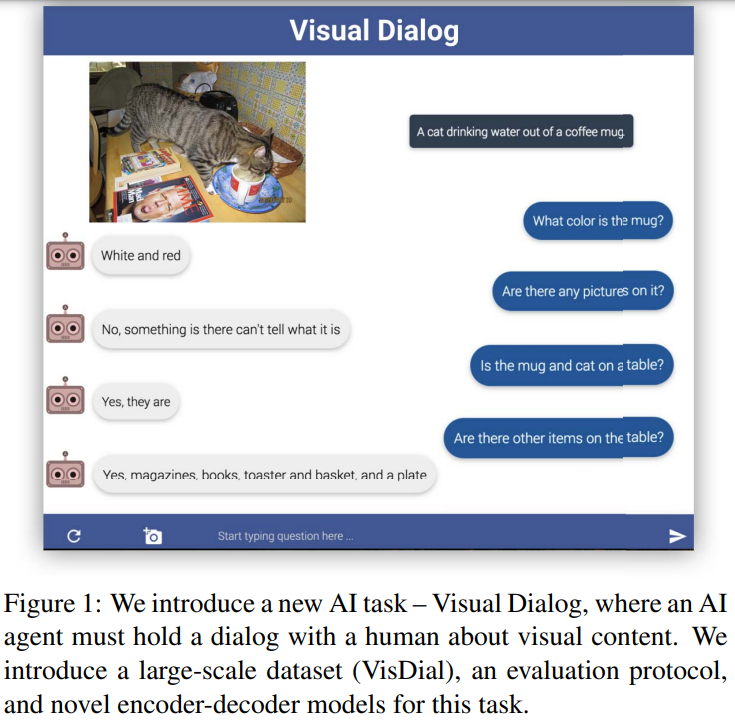
解决方案:
- 视为分类任务,从100个候选答案中选出一个。(ViDialBERT,VDBERT)
- 或视为生成任务,生成正确的答案。(VDBERT)
Visual Linguistic Navigation (VLN)
代表性数据集:
例子:

解决方案:
- 视为分类任务,从一条正确的路和几条错误的路中选出正确的路径。
- 通过RL和imitation learning objective在每个state间预测action。
Image Captioning (IC)
- 任务描述:生成任务,根据图片生成描述文本。
代表性数据集:
- COCO Caption:包含超过330,000图片及对应caption。
例子:

nocaps:来自开放域图片Open Images的用于描述15,100图片的166,100人类生成的caption。
- 例子:

Multimodal Machine Translation (MMT)
- 任务描述:多模态机器翻译,翻译和描述生成的双重任务。它包括将描述从一种语言翻译成另一种语言,并从其他形式(比如视频或音频)中获取额外信息。
代表性数据集:
例子:

未来发展方向
V-L Interaction Modeling
目前在图像、文本对齐上仍有很大挑战。大部分预训练模型在任务层面或输入层面进行masking,这并不能直接实现图像和文本特征的对齐。
Kaleido-bert发现在embedding层面施加mask是有效的。
因此,探索如何显式地对齐图像和文本的embedding特征从而学习更细粒度的表示是很有希望的方向。
VLPM Pretraining Strategy
目前多任务学习策略还缺乏系统性的实验分析,在数据集选择、任务设计、任务分组及多阶段学习中的任务顺序等方面研究较少,没有定论。并且预训练的有效性也会受到下游任务的影响。
Training Evaluation
目前模型的评价只能依靠下游任务,如果能够设计类似perplexity的metric在预训练过程中对模型的性能进行判断将能节省大量资源。
Learning Common Sense and World Knowledge
需求外部知识的V-L任务,例如KVQA、OK-VQA等。
Combining Multiple Tasks
某些任务可以互相转化,从而共享信息。例如visual referring expression任务可以转化为visual dialog task;而image caption generation任务可以转化为visual referring expression任务。
3D-Vision and Language
现有大部分工作都集中于2D图片,而处理3D输入(例如RGB-D、meshes或point clouds)将是一个重要突破。