记录对比多个V-L数据集构建方法,主要包括:Vision-Text Retrieval、Visual Question Answering、Image Captioning、Visual Reasoning、Referring Expression、Visual Dialogue。
MSCOCO
数据集:MSCOCO
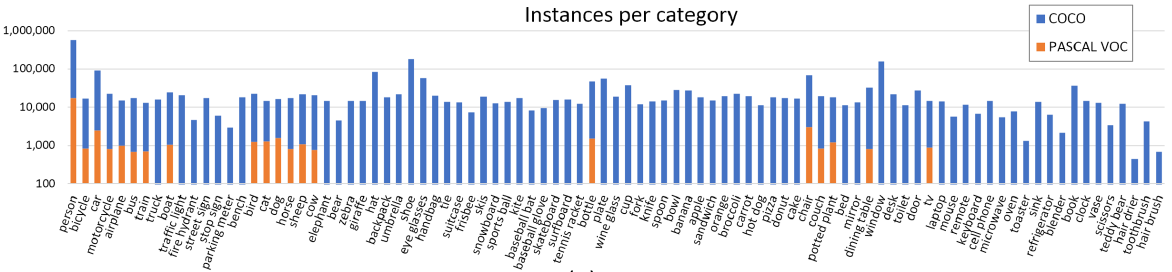
物品类别 (Object Category) 选择
类别范围:物品类别需要具有代表性,同时需要有较高出现频率来支持大数据集的构建。
类别有两大类:thing (包括比较容易标注的物体) 和 stuff (包括天空、草地、街道等没有清晰边界的东西)。这里只选择标注有清晰边界的thing。类别粒度:确定category粒度为entry-level,即人类常用于描述物体的语言。因为过于细粒度的类别不利于搜集足够的图片。
同时有些类别可能被包括在其他的类别之中,例如手、脸都是人体的一部分,这类标注有助于现实世界的应用。类别来源:PASCAL VOC和1,200个最常用的视觉可识别的物体。此外让4-8岁的孩子描述他们看到的室内和室外的物体,得到272个类别。最后由作者根据常见性、应用中的有效性、丰富性等进行1-5分的打分投票。按照投票总数排名选择,同时保证每个大类的平衡性。此外难以获取超过5,000张图片的类别也被删掉。
最后得到91个类别:
非符号化 (Non-iconic) 图像收集
图像可以分为符号化物体图像、符号化场景图像和非符号化图像。具体例子如下:

该数据集主要收集非符号化图像,因为它们的泛化性更好。
采用2种方法搜集图片:
- 仿照PASCAL VOC,从Flickr上收集。(该网站由专业摄影师上传图片,具有可以搜索的metadata和keyword)
- 在搜索引擎中搜索两个类别物体名的组合或者类别和场景名的组合,这是因为单独搜索一个类别名返回的大部分都是以该类别的一个实例为中心的符号化图像,而组合搜索则会返回更多非符号化图像。在无法搜索到足够的一个类别图片时,会搜索单个类别名,同时增加审查阶段过滤掉其中的符号化图像。
最后收集到328,000张图片。
图像标注
包括以下三步:
Category Labeling:将91个类别分为11个大类,对每张图片,标注者首先要依次判断该图片里是否有每个大类的物体,如果有,则需要标注者将该大类下具体的小类别标识拖到图片中的一个该类别的实例上。每张图片有8个人标注,只要有1个人认为类别存在就将其认为存在。(这一步花费大约20k worker hours)
Instance Spotting:对每张图片,标注者需要将×标志放到该图片中一个类别的所有实例上(这里的类别来自第一步标注)。为了增加召回率,第一步标注出的类别的一个实例也被显示给这一步的标注者。对于一张图片和一个类别,每个标注者最多只能标10个实例,每张图片8个人标注。(这一步花费大约10k worker hours)
Instance Segmentation:要求标注者按照前一步的实例位置标注进行实例分割,如果图片上已有其他实体分割的标注也会同时显示给标注者。标注者可以标出当前图片中不存在该实例或者所有实例都已分割完。这一步标注每1000个分割需要22个worker hour,因此每个实例只有一个标注者标注。在开始前有训练阶段,要求标注一个实例的完整的分割,直到完全标注正确为止。此外还有3~5个标注者被要求判断每个实例分割是否正确。无效标注被要求重新标注。在实例少于10个的图片中,每个实例单独标注;在包含更多实例的图片中,超过10-15个实例被标注后,其他实例被一起标注为crowds。
描述标注
此外还给每个图片标注了5条描述,具体标注过程见COCO Caption。
Image Captioning & Image-Text Retrieval
数据集:COCO Caption
使用来自MS COCO的图片,由于其中包括复杂的信息,适合作为IC的图片源。
训练、开发、测试集的分割与MS COCO原始分割相同。
包括两个数据集:
- MS COCO c5:MS COCO训练、开发、测试集中的每张图片对应5个描述;
- MS COCO c40:MS COCO测试集中随机sample的5,000张图片中每个对应40个描述。创建该数据集是因为很多自动评价指标在参考句子更多的时候和人类评价的一致性更好。
使用Amazon’s Mechanical Turk (AMT)众包标注,标注页面如下所示:
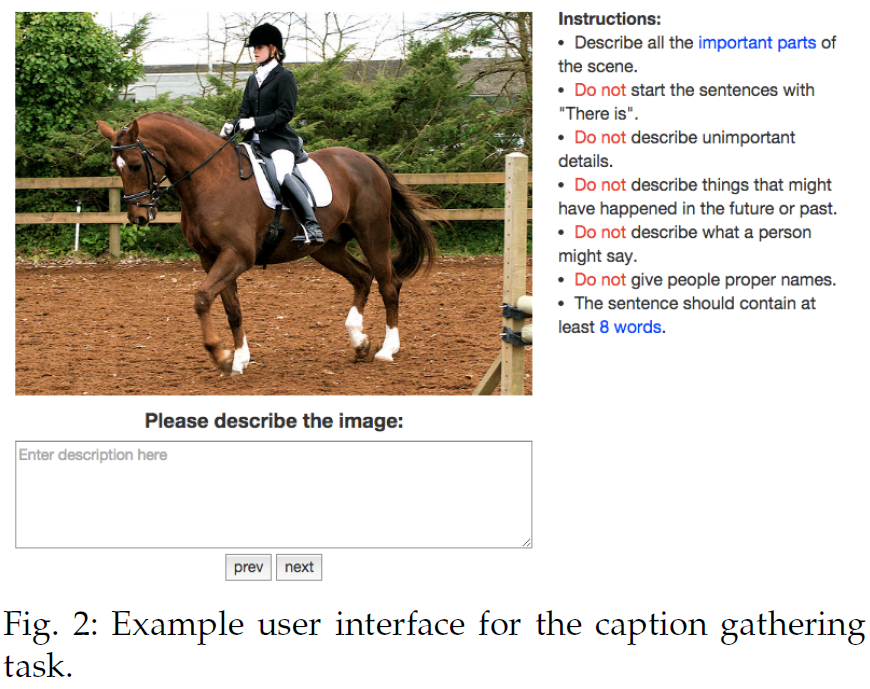
标注要求包括:
- 描述场景中的重要部分;
- 不要使用“There is”开头的句子;
- 不要描述不重要的细节;
- 不要描述可能发生在过去或未来的事;
- 不要描述图中人可能说的话;
- 不要给图中人命名;
- 句子至少要有8个词。
具体标注数据如下:
413,915 captions for 82,783 images in training, 202,520 captions for 40,504 images in validation and 379,249 captions for 40,775 images in testing including 179,189 for MS COCO c5 and 200,060 for MS COCO c40.
使用的自动评价指标包括:BLUE、ROUGE、METEOR、CIDEr。
数据集:Flickr30K
所有标注规范都模仿Framing Image Description as a Ranking Task: Data, Models and Evaluation Metrics。
每张图片由5个独立的标注者分别写一个描述,标注者不了解图片中的实体和环境,因此会使用客观方式描述。
Visual Question Answering
数据集:VQA
真实图片
图片来源是MS COCO的123,287张训练集和81,434张开发集图片。由于COCO中搜集的图片都具有复杂的上下文信息,适用于VQA任务。
抽象场景 (abstract scene)
新构建了50K抽象场景数据集,该数据集包含20个性别、种族、年龄不同的paperdoll人类模型(类似于贴画娃娃)和8种不同的表达。人类模型的肢体是可以调整的。同时包括不同动作的超过100种物体和31种动物。
数据分割
采用和MS COCO一样的train/test-dev/test-standard/test-challenge/test-reserve的分割方法,其中test-dev用于debug和开发。test-standard用作默认测试数据。
问题收集
收集问题需要考虑到以下几点:
- 问题不能太简单,只使用CV知识就能回答,例如“猫的颜色”;
- 要保证问题的回答需要图片信息,而不能不借助图片直接就能回答正确,例如“胡子是什么组成的”。
经过对标注者不同的要求测试,最终要求为:
“We have built a smart robot. It understands a lot about
images. It can recognize and name all the objects, it
knows where the objects are, it can recognize the scene
(e.g., kitchen, beach), people’s expressions and poses, and
properties of objects (e.g., color of objects, their texture).
Your task is to stump this smart robot!
Ask a question about this scene that this smart robot
probably can not answer, but any human can easily
answer while looking at the scene in the image.”
总结起来就是我们建了一个聪明的机器人,能够识别、定位所有物体和场景,包括人的表达的动作和物体的属性。标注者的任务是提出问题难住这个机器人,但同时提出的问题又需要人类一看图片就很容易能回答出来。
另外标注者也被要求问题必须要是根据图片才能回答的。
总的来说,每张图片对应来自各自独立标注者3个问题,标注者在标注时可以看到针对该图片已经标注过的问题,从而增加问题的丰富度。
答案标注
为了处理一个问题多种可能答案都是正确的情况,对每个问题收集10个来自各自独立标注者的答案,并保证回答问题的不是问问题的人。
要求标注者使用短语而非完整句子回答,要实事求是地回答,避免使用口语式回答或加入自己的看法。
同时标注者要先选择自己是否能够回答该问题。
对于开放域问答:如果有3个人及以上都回答了一个问题,则认为该回答是正确的。最终有89.32%的答案都是一个词组成的。
对于多项选择:每个问题对应18个候选答案,每个选项的accuracy是按照选该选项的人除以3确定的 (最大为1)。
候选答案从以下4类答案中获取:
- Correct:出现频率最高的正确答案;
- Plausible:这类是看起来是对的答案,这种答案是让3个标注者在不看图片的情况下回答问题生成的;
- Popular:10个最常用的答案 (包括:”yes”, “no”, “2”, “1”等);
- Random:来自数据集的随机问题的答案。
数据集:VQA2.0
该数据集主要是为了解决VQA中的偏置问题。与VQA相比,该数据集中每个问题对应两张具有不同回答的图片。

VQA2.0数据建立在VQA基础上,VQA包括超过204K图片,共614K个自然语言问题(每个图片3个问题),对应超过六百万答案(每个问题10个答案)。
具体构建方法为:对VQA中的每个图片I-问题Q-答案A对,找到另一张与原图I相似的图片,其对原问题Q的答案与A不同。
标注页面如下:

标注者要从原图片的24张nearest-neighbor图片中选出一张,使问题Q对其是有意义的,且答案不为A。
24张最近邻图片是通过将图片表示为VGGNet中penultimate (‘fc7’) layer的activation,然后和原图片计算l2距离获得的。
在获取补充图片后,对每个新的图片-问题对,让10位标注者写下答案,其中出现最多的作为新图片-问题的答案。
在24张最近邻图片中问题Q都无效或没有图片对应的答案与原答案不同时,标注者可以选择跳过。
共收集了195K、93K、191K张补充图片分别加入训练、开发和测试集。
因此,完整的数据包括443K训练、214K开发和453K测试集的图片-问题对。
Visual Dialogue
数据集:VisDial v0.9/v1.0
使用的图片来源是COCO,因为其中的图片大多包含多个物体,其图像复杂性能引发有趣、丰富的对话。
实时聊天界面
符合任务要求的优质数据应该具有以下特点:
- 时间上是连续的;
- 与图片有关联;
- 模仿自然的交流沟通。
让AMT上的两个标注者进行实时交谈,其中一个作为提问者,只能看到一句描述图片的话(COCO中的caption)而看不到图片。提问者需要通过问问题增强对图片的了解(imagine the scene better)。另一个作为回答者,能同时看到描述和图片,需要回答提问者的问题。与VQA不同的是不要求答案尽可能简短,而是要求尽可能自然地进行讨论。这是一个无约束的实时聊天场景,唯一要求是提问者必须等前一个问题被回答之后再提下一个问题。在互相问答超过10轮之后,标注者可以选择停止。
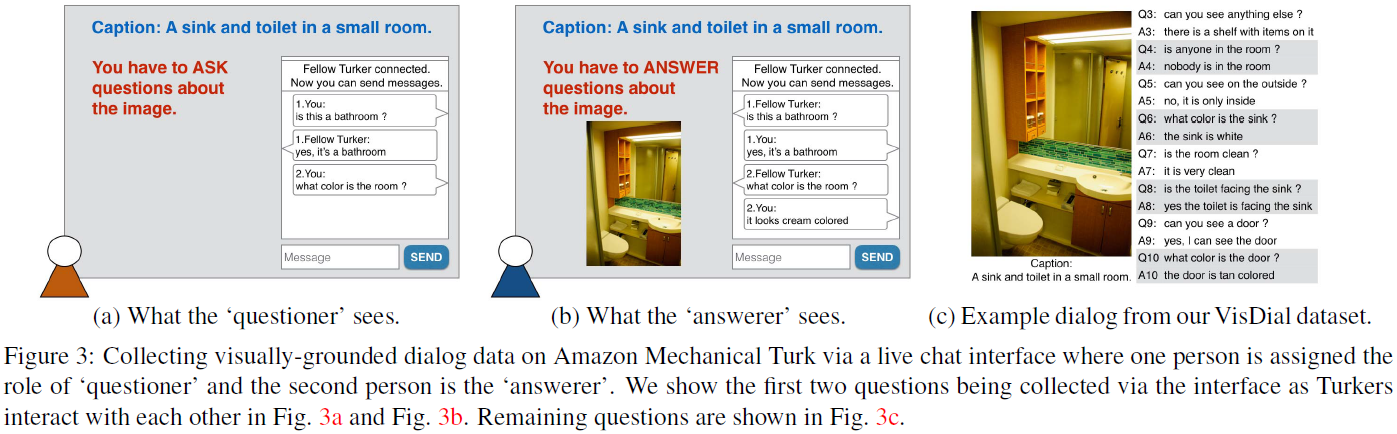
此外还尝试过给提问者看高度模糊的图片代替描述,但结果的对话没有只显示描述自然。因此最终选择只显示描述的方法。
AMT上2人聊天支持
由于AMT不支持多人交互界面,作者实现了2人实时聊天界面,并公布了代码。
如果其中一个人中途离开,另一个人被要求问完10个问题或者给出10个关于图片的事实,并被正常支付。但该组数据将被丢弃,图片被分配给另外一组标注者重新标注,从而保证数据都是真实聊天数据。
评价指标
由于BLUE、METEOR、ROUGE等自动评价指标与人类评价相关性很差,该数据集以每轮问答为单位,采用检索/多项选择结果进行评价。
具体来说,对第k轮对话,给出其相关图片1张、前面的k-1轮对话历史、图片caption以及100个候选答案,要求模型返回候选答案的排序。
从以下4个集合中搜集候选答案:
- Correct:正确答案;
- Plausible:对50个最相似的问题的答案,相似问题定义是开头具有相似的tri-grams,同时后面的语义内容相似。具体来说就是将前3个词的GloVe embedding拼接起来,再拼接后面所有词的平均GloVe embedding。然后计算和原问题的欧几里得距离。这类答案称为“hard negative”;
- Popular:30个数据集中出现最频繁的答案,例如“yes”,“no”等;
- Random:剩余答案是对数据集中随机问题的答案,在搜集时首先获取上述三种答案的并集,然后补充随机答案直到达到100个候选答案。
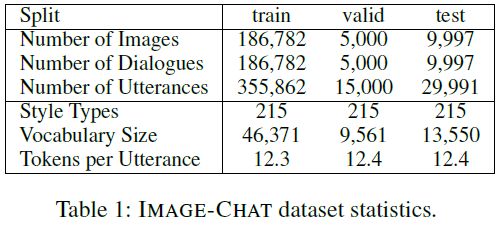
数据集:Image-Chat
包括(图片,对话者A的风格特征,对话者B的风格特征,A和B的对话)四元组组成的数据集。除了需要按照风格特征进行对话并尽量保证有趣(in an engaging way)外,对话内容没有其它约束。
风格特征
对于Image Captioning任务,有研究表明使用风格特征能够帮助生成有创造性的描述。使用现有的定义好的215个可能的风格特征,主要分为以下三类:
- positive:sweet, happy, eloquent, humble, witty;
- neutral:old-fashioned, skeptical, solemn, questioning;
- negative:anxious, childish, critical, fickle, frivolous。
将这些风格特征分别分配给A和B,对一段对话分别给AB分配不同的风格特征。
图片
本数据集的图片来自于YFCC100M数据集中的随机采样。
对话
对每张图片,随机选取两种风格特征分别分配给A和B,然后让两个标注者分别按照分配的风格特征就图片开展对话。在标注规范中强调这里的风格特征描述的是对话者的特征,而非图片的特征。
数据质量
在标注过程中,标注者被人工监督,检测其是否遵守标注规范。不遵守的标注者被取消,其标注内容也被丢弃。
之后有额外的标注者被要求判断从已标注数据中随机选择的样本的对话是否符合给定的风格特征和图片。这部分评价中发现92.8%匹配图片,83.1%匹配风格,80.5%都匹配。
下面是搜集图片的数据:
Visual Grounding
数据集:RefCOCO/RefCOCO+
ReferItGame
该数据集通过这种两人互动游戏构建,首先给A标注者一张标有目标物体的图片,要求其用语言描述,之后B标注者被要求根据图片和描述点击对应的图片。如果B标注正确则得分并交换位置。
图片和标签
原始数据集不是在COCO上构建的,而是在ImageCLEF IAPR image retrieval dataset上,该数据集包括20,000张图片。而其SAIAPR TC-12 expansion(扩展版)中包括了每张图片中构成对象的segmentation标注。包括238种动物、人类、建筑、物体和场景标签。
数据收集
使用上述ImageCLEF数据集构建了超过100k独立游戏(每个游戏有一个被标出来的物体)。
为了先标注更有趣的表达,优先标注图片中存在一个类别的多个实体的游戏。在这些都标完之后,再根据物体类别排序,尽可能包含更大范围的不同类别的物体。最后再标注剩下的。
为了验证一致性,在标注过程中有一定比例出现此前已经标注过的游戏。
数据集:RefCOCOg
直接在MS COCO(COCO上也有实例级别的物体分割标注)上构建的RE数据集,主要解决的是RefCOCO中两个问题:(1) 有的图片中只有一个类别的一个实例,因此可以用很简单的语言在没有歧义的情况下描述目标物体;(2) ImageCLEF数据集主要集中在“stuff”(环境)而非“things”(物体)。
选择图片中符合以下条件的物体:
- 图中存在同一个类别的2-4个实例;
- 图中实例的bounding box至少占整个图片的5%。
得到26,711张图片中的54,822个实体。
在Mechanical Turk上建立一个任务,给出一张图片和其中一个用highlighting object mask标出的物体,要求标注者写一句话单独描述被标出来的实体。
之后建立另一个任务,给出一张图片和上面任务写下的描述,要求标注者选择描述的物体。如果选择的位置在原始物体的segmentation mask之内,则将该标注认为是有效,否则将该标注抛弃,让其他标注者重新标注。
在Mechanical Turk上重复交替执行上述两个任务(最多3次),最终收集到104,560个描述,平均每个物体有1.91个描述,每张图片有3.91个描述。
Visual Reasoning
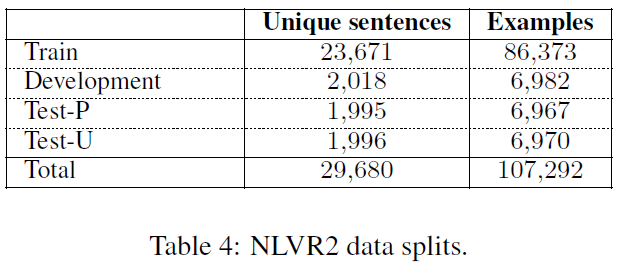
数据集:NLVR2
该任务为给定两张图片,判断描述的文本是否正确。
图片收集
根据任务特点,需要搜集互相具有相似性的,且比较起来需要一定推理能力的图片。而现有的ImageNet、COCO等图片源中没有这种成组的图片,且大多是相对简单的集中于目标物体的图片。
因此使用ILSVRC2014 ImageNet challenge中的同义词作为搜索query检索具有相似内容的图片。
具体包括以下几步:
- ImageNet Synsets Correspondence:从ILSVRC2014中的1,000个同义词集合中选出一个经常出现在丰富上下文中的子集。对其中每个synset,使用query expansion heuristic构建5个query。heuristic设计的目标是检索出支持复杂推理、包括多个实体、复杂环境或实体参与某项活动的图片。例如:acorn的expansion包括two acorns和acorn fruit。然后使用Google similar images tool对每个query检索到的前5张图各检索7张与其不重复的最相近图片。这样每个query共获取了5组每组8张图片,而总共有25组。如果按照下图中的标注规范一组中超过一半的图片都被标注为有趣,则该synset加一分。最后选取得分最多的124个synset。这一步只是为了确定synset,由作者和学生完成。


- Image Search:使用谷歌图片搜索引擎检索图片。将generation heuristic应用到124个synset上,对每个synset使用其中所有的近义词。例如:对timber wolf,使用近义词集合{timber wolf, grey wolf, gray wolf, canis lupus}。对每个query,搜集最多16张相关图片。具体来说,首先使用搜索引擎获取query相关图片,然后使用Google similar images tool检索与该图片相似的图片。

- Image Pruning:1)通过众包去掉收集的图片集合中的低质量图片:向标注者展示synset name和所有图片集合,要求去掉其中包含不适合的内容,非现实图片、拼贴画或不包含synset对应实例的图片。最终获得不多于16张图片的集合,如果剩余图片少于8张将被丢弃。2)通过众包去掉不有趣的图片:按照Table 2中的规则判断图片是否有趣,同时还要去掉重复图片。最终丢弃有趣图片少于3张的集合。将图片按照有趣程度排序,保留前8张(这里的意思应该是从左边开始先是有趣的图片,然后是不有趣的,然后从左边选8张)。

描述收集
在前一步获得了每组8张的图片集合,在这一步首先随机将每组分成4对2张图片组成的图片对。(成对的图片能鼓励两张图片间的对比和推理。)
标注者需要从4对图片中选出2对,然后写一个句子,使其对被选中的2对图片是对的,但对未被选中的2对图片是错的。(让标注者自己选择比随机分配更能降低生成无效图片对的概率)
写的句子需要描述图片对的相似性和区别,鼓励使用compositional language。

要求标注者在写描述句子时需要避免:
- 主观意见;
- 讨论照片的特点(例如,在两张图里猫爪都伸出了照片);
- 描述图片中出现的文本;
- 描述在未选择的图片中不存在的物体;
- 描述单一物体(例如,图中有一个锤子);
- 分别描述两张图片(例如,左边图有一个人,右边图有一只狗)。
下面给出具体对应的例子:

验证过程
将上一步的每个描述句子和其对应的4对图片分别组合形成4个例子,让标注者独立判断每个例子的描述是正确还是错误,标注者还可以选择该例子是无意义的。最终只保留没有被标注为无意义且新标注的标签和原来写的标签相同的句子。
数据划分
随机选择20%通过验证的例子作为开发和测试集。同时保证最初来自一个8张图片组的图片不被分别划分到2个部分。(对这部分数据,每个例子额外增加4个验证标注,如果有2个或更多验证标注和原始标注不同,则删除该例子)然后将通过的例子平分成1个开发集和2个测试集,保证初始的图片组(由类似图片组成的组)不出现在多个集合中。
数据收集管理
- 对于图片收集和描述收集任务:首先展示6个针对标注规范的辅导问题,然后要求他们验证来自2组的4个预先选择的图片对的19个句子,并完成一个独立的描述写作任务。最后人工评价标注者写的句子。
- 对于描述验证任务:让标注者验证8个预先选择的例子。
为了鼓励标注者按照规范书写尽可能具有语言多样性的句子,标注过程分为多个阶段。每个阶段结束时从每个标注者当轮标注的句子中随机选取20个,按照其中符合规范的百分比提供不同的奖励。
此外,每个标注者最开始只能进行有限的描述写作任务,当其在一轮中符合规范的句子超过75%时,其才能进行所有任务。
最后获取的样本数量为: