2019年-2021年大规模预训练模型对比,从最开始2019年的8.5B的Megatron,到最近2021年底的280B的Gopher。
模型信息
| 模型名称 | 发表日期 | 语言 | 模型参数 | 模型结构 |
|---|---|---|---|---|
| Megatron | 2019.09 | English | 8.5B | BERT/GPT |
| T5 | 2019.10 | English | 11B | encoder-decoder |
| GPT-3 | 2020.03 | English | 175B | GPT |
| Switch Transformer | 2021.01 | English | 26.3B | T5 |
| Jurassic-1 | 2021.08 | English | 178B | GPT |
| Megatron-Turing NLG | 2021.10 | English | 530B | transformer-decoder |
| Gopher | 2021.12 | English | 280B | GPT |
| GLaM | 2021.12 | English | 1.2T | transformer-decoder |
| CPM | 2020.12 | Chinese | 2.6B | GPT |
| M6 | 2021.03 | Chinese | 100B | unified-transformer |
| PanGu | 2021.04 | Chinese | 200B | GPT |
| CPM-2 | 2021.06 | Chinese | 11B | MLM+encoder-decoder |
| HyperCLOVA | 2021.09 | Korean | 82B | GPT |
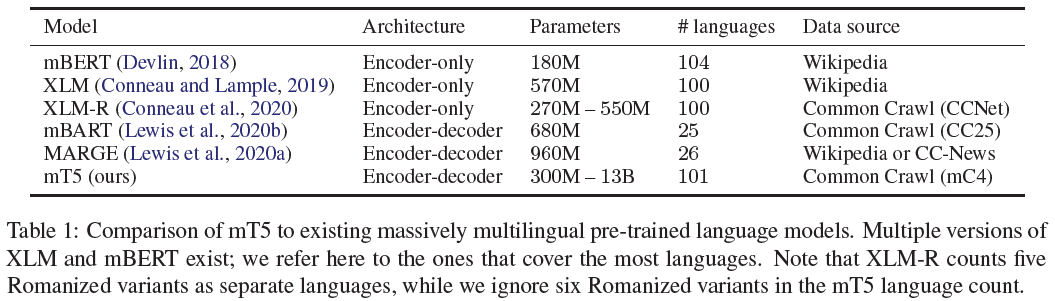
| mT5 | 2020.10 | 101 Lans | 13B | T5 |
数据信息
| 模型名称 | 模型参数 | 数据规模 | 是否公开 |
|---|---|---|---|
| Megatron | 8.5B | 174G | 否 |
| T5 | 11B | 750G | 是 (C4) |
| GPT-3 | 175B | 570G | 否 |
| Switch Transformer | 26.3B | 750G | 是 (C4) |
| Jurassic-1 | 178B | 300B toks | 否 |
| Megatron-Turing NLG | 530B | 270B toks | 部分 |
| Gopher | 280B | 300B toks | 否 |
| GLaM | 1.2T | 1.6T toks | 否 |
| CPM | 2.6B | 100G | 否 |
| M6 | 100B | 292G | 否 |
| PanGu | 200B | 1.1T | 否 |
| CPM-2 | 11B | 2.3T(zh)+300G(en) | 部分 (200G) |
| HyperCLOVA | 82B | 560B toks | 否 |
| mT5 | 13B | 6.3T toks | 是 (mC4) |
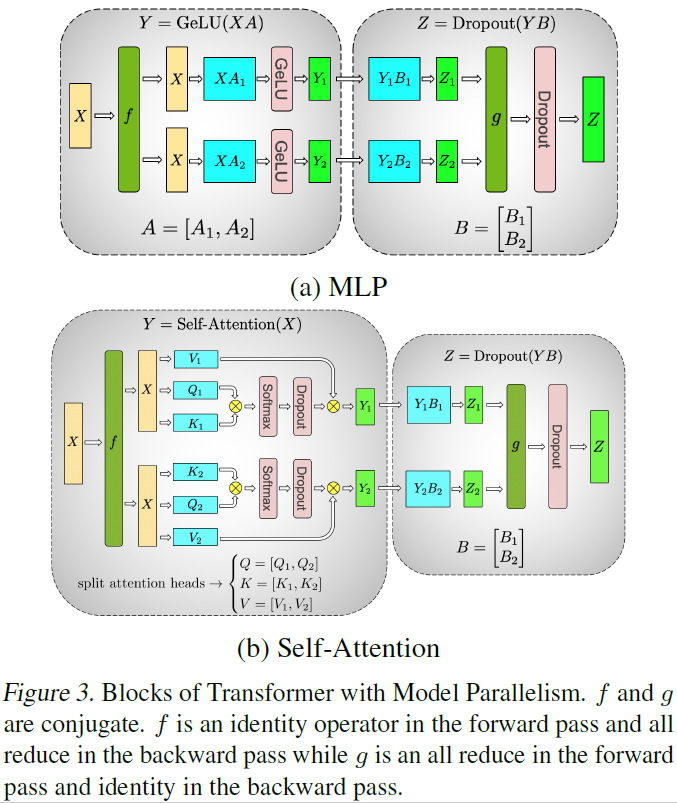
Megatron-LM
论文题目:Megatron-LM: Training multi-billion parameter languagemodels using model parallelism
单位:NVIDIA
主要贡献:
- 提出了一种简单高效的模型并行方法,支持百万级别参数的模型的训练;
- 使用本文提出的模型并行方法和数据并行方法,用512个GPU训练了8.3B的GPT-2模型和3.9B的BERT模型。
数据:
We create an aggregate dataset consisting of Wikipedia (Devlin et al., 2018), CC-Stories (Trinh & Le, 2018), RealNews (Zellers et al., 2019), and OpenWebtext (Radford et al., 2019). For BERT models we include BooksCorpus (Zhu et al., 2015) in the training dataset.
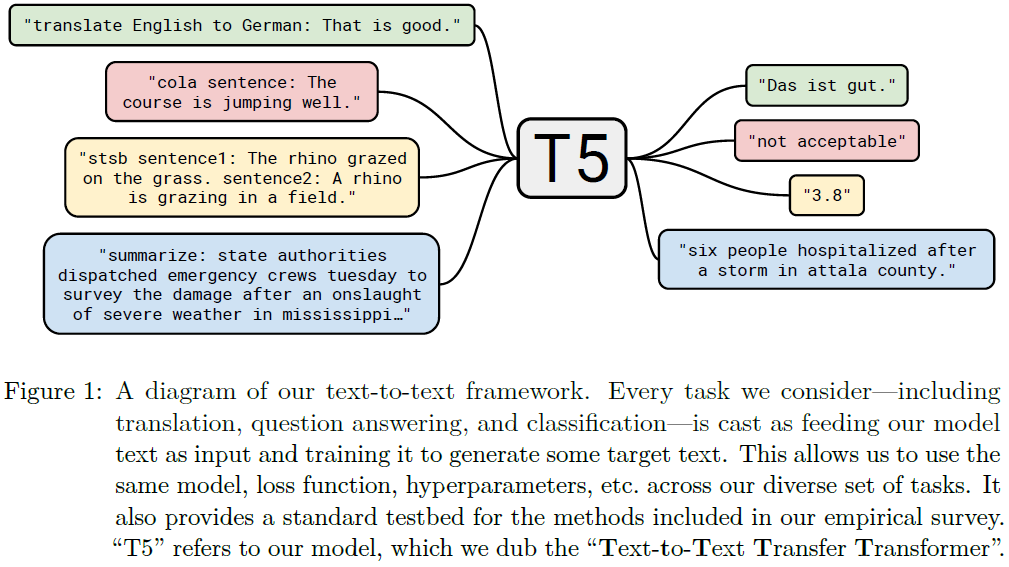
Text-to-Text Transfer Transformer (T5)
论文题目:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
单位:Google
主要贡献:
- 提出一种通用框架,将所有NLP任务转化为Text-to-Text,从思想上可以认为是prompting的先驱者;
- 公开了一份大规模高质量的预训练语料Colossal Clean Crawled Corpus (C4);
- 进行了大量的预训练模型,setting实验,最终选择encoder-decoder结构并给出推荐参数。
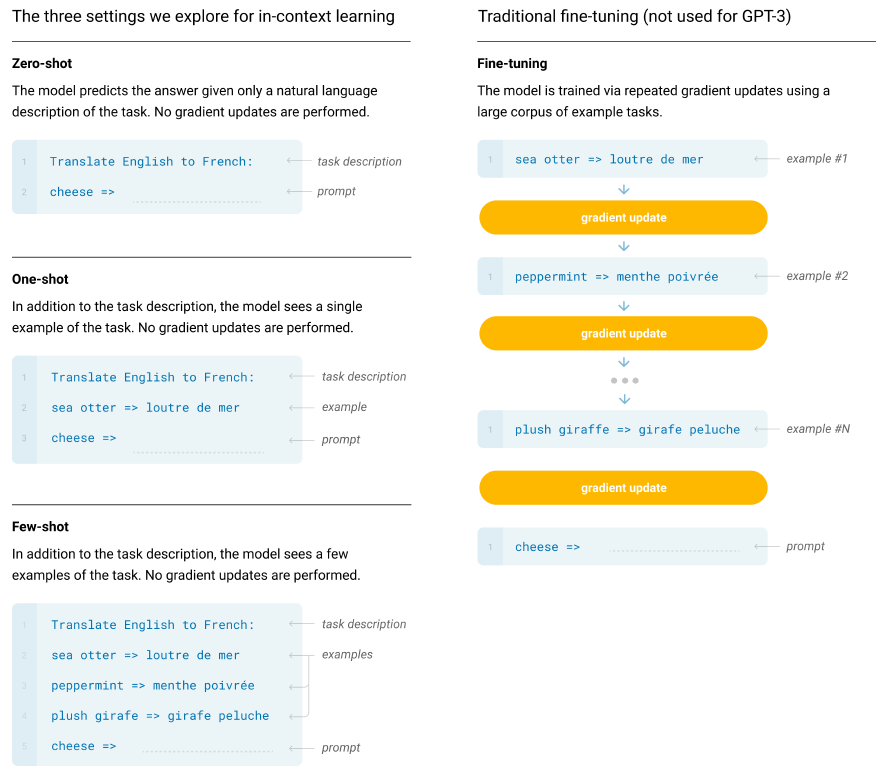
GPT-3
论文题目:Language Models are Few-Shot Learners
单位:OpenAI
主要贡献:
- 正式提出prompting的概念,在大规模预训练模型的基础上仅通过few-shot learning甚至zero-shot learning就实现了较高性能;
- 模型结构与GPT-2相同,但参数规模达到了175B。
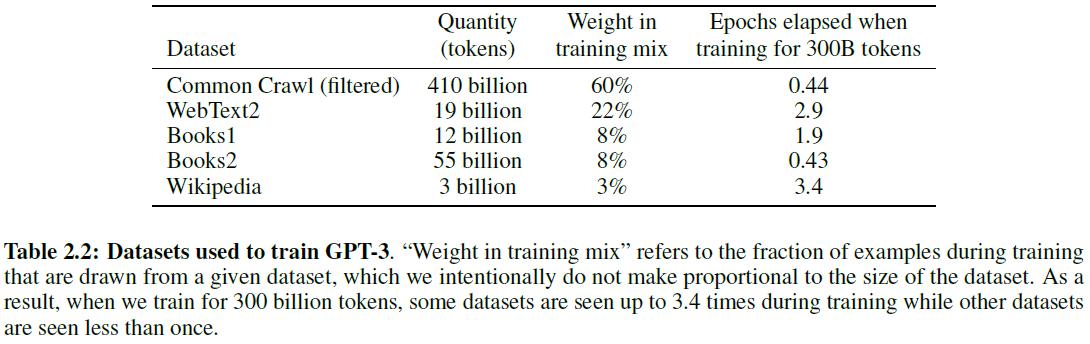
数据:
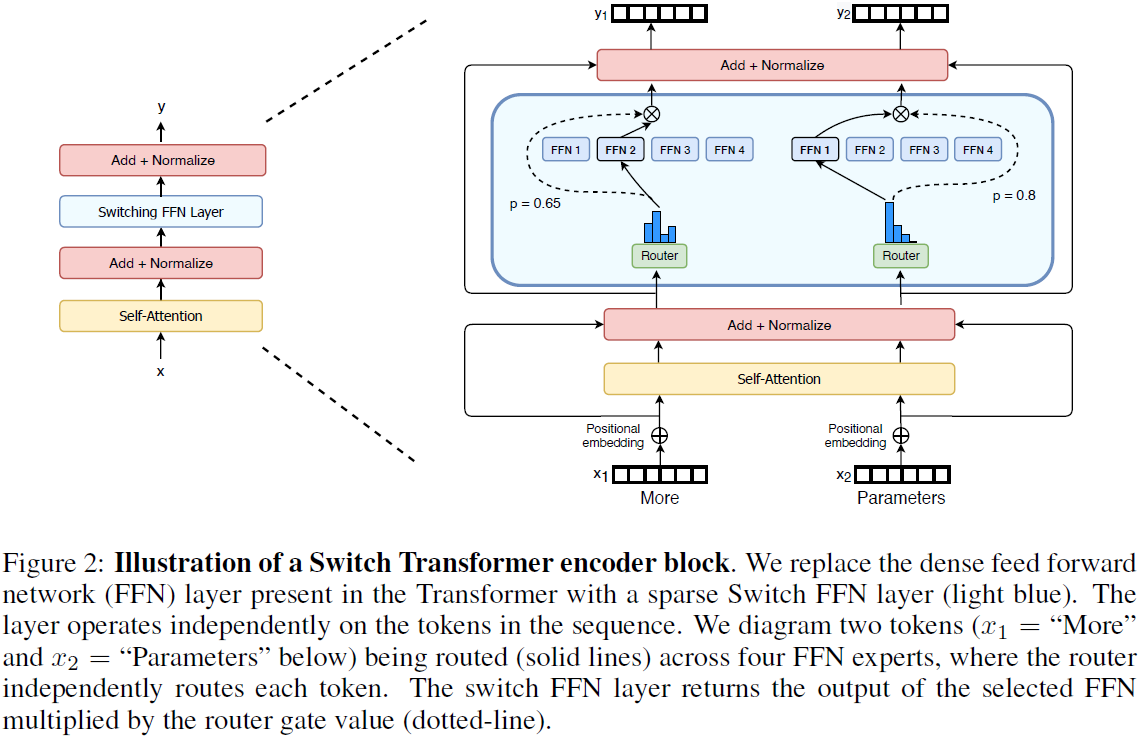
Switch Transformer
论文题目:Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
单位:Google Brain
主要贡献:
- 通过简化Mixture of Experts (MoE) routing算法,降低了通讯和计算损失 (communication and computational costs);
- 使用C4数据训练了26.3B的T5模型。
Jurassic-1
论文题目:Jurassic-1: Technical details and evaluation
单位:AI21 Lab
主要贡献:
在GPT-3模型结构的基础上做出了两点改变
- 参考Limits to Depth-Efficiencies of Self-Attention中的结论,将GPT-3中的层数从96层降为76层,由于将模型深度转换为跨度,加快了推理速度 (平行运算比GPT-3更多) ;
- 使用T5使用的SentencePiece tokenizer,训练一个超过GPT-3 (50K) 词典大小的256K词典,加快了分词速度。
Megatron-Turing NLG
单位:NVIDIA
主要贡献:
- 目前最大预训练模型,结构上仍然沿用transformer decoder单向语言模型,同时使用prompt。主要贡献是模型并行,但是似乎并没有具体说明,只有一个blog。
Gopher
论文题目:Scaling Language Models: Methods, Analysis & Insights from Training Gopher
单位:DeepMind
主要贡献:
在GPT-2模型的基础上做了2点改进
- 用RMSNorm (Root Mean Square Layer Normalization)代替了LayerNorm;
- 用相对位置向量代替了绝对位置向量。
其他:
- tokenizer也换成了SentencePiece,词典大小为32,000;
- 同时测试了fine-tuning和prompting;
- 使用JAX实现模型、数据并行,使用TPUv3训练。
结论:
- 模型规模的收益不是平均的,某些需要更复杂的数学或逻辑推理的任务上,Gopher模型规模增加无法带来显著的效果提升。
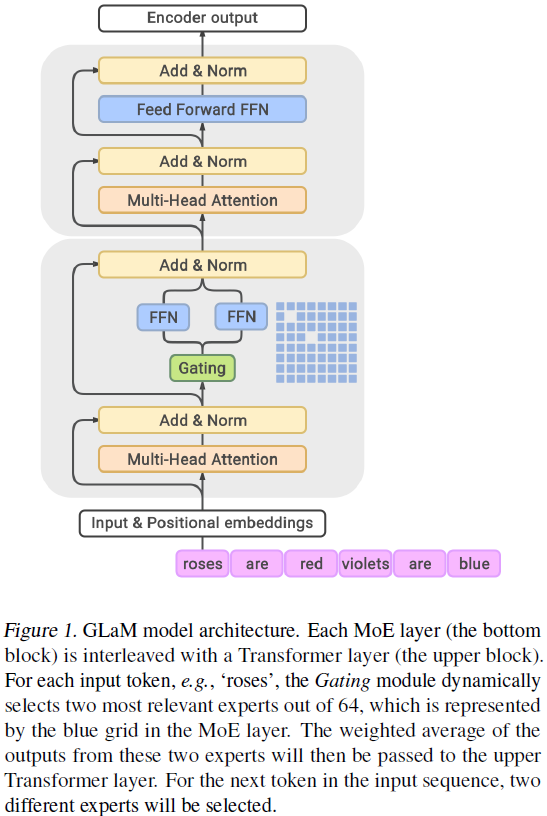
GLaM
论文题目:GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
单位:Google Inc
主要贡献:
- 提出一种sparsely activated MoE结构用于增大预训练模型容量,同时训练该模型的资源消耗远小于同样的dense模型;
- 最大模型达到1.2T。
CPM
论文题目:CPM: A Large-scale Generative Chinese Pre-trained Language Model
单位:Tsinghua University, Beijing Academy of Artificial Intelligence (BAAI)
主要贡献:
- 训练了2.6B的autoregressive LM模型CPM;
- 为适应中文使用了新的基于中文分词的词表,并使用3072 batch size。
其他:
- 使用中仍然延续了GPT-3的prompt思想。
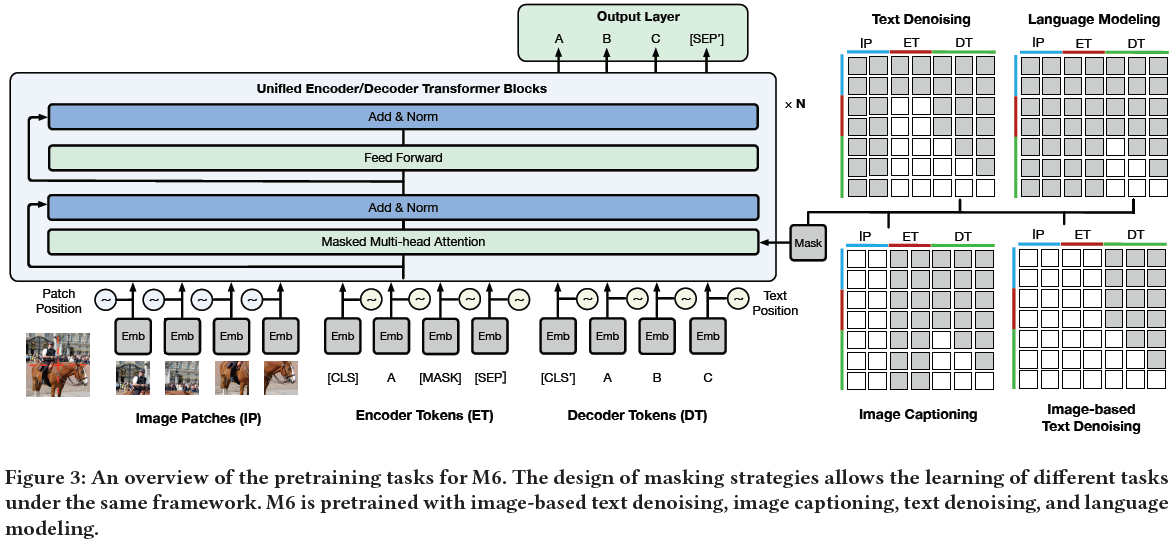
Multi-Modality to Multi-Modality Multitask Mega-transformer (M6)
论文题目:M6: A chinese multimodal pretrainer
单位:Alibaba Group, Tsinghua University
主要贡献:
- 使用了2T的图片和300G的文本用于中文多模态预训练模型训练。
其他:
- 使用了Megatron-LM提出的模型并行方法;
- 在100B版本的模型中也使用了MoE策略,使用Whale实现,支持GPU并行;
- 测试了fine-tuning和prompting两种方法。
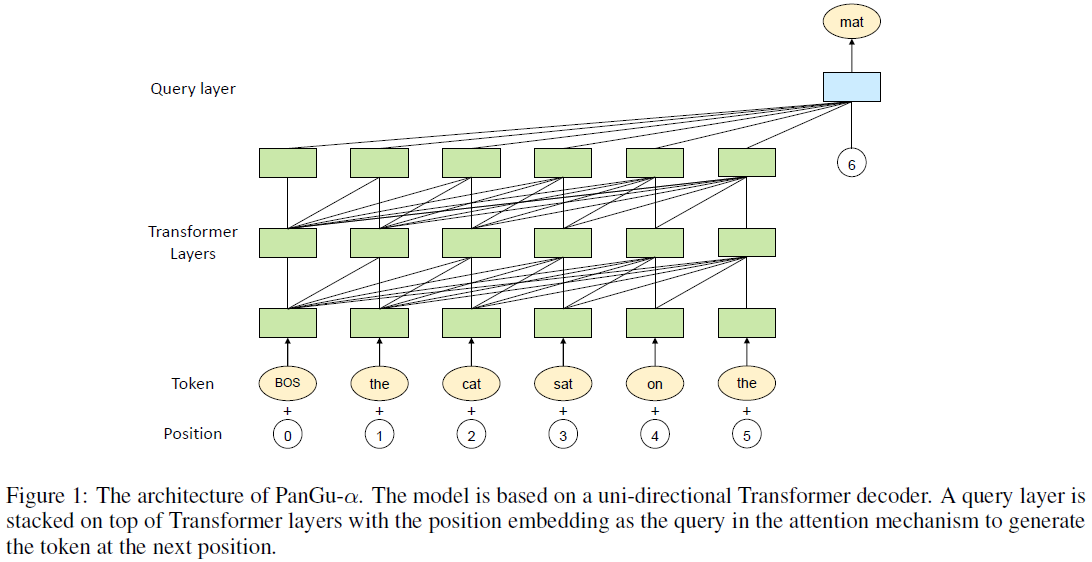
PanGu
论文题目:Pangu-alpha: Large-scale autoregressive pretrained chinese language models with auto-parallel computation
单位:华为云,循环智能
主要贡献:
- 使用MindSpore实现了5个维度的自动并行,包括数据并行、op-level模型并行、pipeline模型并行、optimizer模型并行和重计算 (rematerialization),在2048个Ascend 910 AI processors上训练了200B预训练模型;
- 在transformer层上额外加了一个query layer,用于预测下个token。
CPM-2
论文题目:CPM-2: Large-scale Cost-effective Pre-trained Language Models
单位:Tsinghua University, Beijing Academy of Artificial Intelligence (BAAI)
主要贡献:
- 使用knowledge inheritance (Knowledge inheritance for pre-trained language models) 加速预训练过程。即利用已有的预训练模型帮助预训练新的模型,避免了从头开始训练浪费大量计算资源。
- 使用prompt tuning (The Power of Scale for Parameter-Efficient Prompt Tuning) 代替传统fine-tuning减少针对具体任务的参数量。该方法中针对每个具体任务微调时会固定预训练模型,只训练prompt token的向量,其参数量只占整个模型的0.01%。
- 使用Mixture-of-Experts (MoE) 技术 (Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, BASE Layers: Simplifying Training of Large, Sparse Models) 训练198B的大规模预训练模型,并设计高性能、内存利用率高的推理框架INFMoE,实现了在单GPU上运行MoE模型。
其他:
- 模型结构上采用了MLM encoder-decoder框架,其思路跟GLM (All NLP Tasks Are Generation Tasks: A General Pretraining Framework) 比较像,在encoder中随机用特殊token代替span,在decoder中预测这些span;
- CPM-2-11B和CPM-2-MoE (198B)模型均支持中英双语,使用WuDaoCorpus2.0 (2.3TB中文,300GB英文) 训练。
HyperCLOVA
论文题目:What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
单位:NAVER
主要贡献:
- 韩语版GPT-3,使用韩语560B token语料训练的82B GPT-3模型。
mT5
论文题目:mT5: A massively multilingual pre-trained text-to-text transformer
单位:Google Research
主要贡献:
- 13B参数量的多语言版本T5;
- 公布了包含101种语言的27T预训练语料mC4。
mT5和其他多语言预训练模型对比。